How do Search Engines work?: SEO made easy for beginners
How do Search Engines work?: SEO made easy for beginners
What is a Search Engine?
Assume that you are in a library and you are searching for a book. Consider some cases:
- You know the exact title and author of the book. In that case, you ask the librarian to show you the reader directly. It’s just like typing https://www.companyname.tld. You need to know the company name and its domain extension, like .com,.in,.co.uk,.org etc., otherwise called a top-level domain (TLD)
- You know the name of the book but not its author. In this case, the librarian will show all the books with that title in the most relevant order. It’s the same as you searching a company name in Google and getting the SERP (search engine results pages). Most often, you will find the company’s website you are looking for in the top 10 results.
- You don’t know the book’s name and author but want to read a particular genre. In that case, the librarian will suggest all existing books in that genre. It’s like you searching for the best digital marketing blog and finding digitalsbyashwan.com as one of the results.
I am not sure which page you will find it right now 🤣 but you surely will.
The world wide web is the most extensive library you enter when you use the Internet and you will be confused with the amount of data in the www repository. You will need a librarian, in this case, the Search Engine, to help you find the relevant books/information.

Definition of a Search Engine:

A search engine is a software designed to match and sort the results from a database/repository based on the search query from the user.
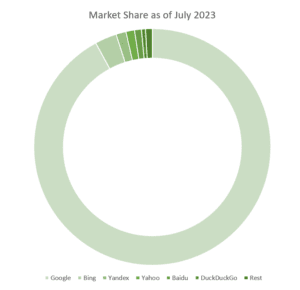
When we hear about a search engine, we remember Google. But in reality, there are many more of them:
- Google: 92.08% of the market share
- Bing: 2.98%
- Yandex: 1.36%
- Yahoo: 1.17%
- Baidu: 0.94
- DuckDuckGo: 0.56%
- Google: 92.08% of the market share
- Bing: 2.98%
- Yandex: 1.36%
- Yahoo: 1.17%
- Baidu: 0.94
- DuckDuckGo: 0.56%
While we have learnt what a search engine is, we still do not know how it does its job. There are three steps that any search engine follows.
Crawling: what is search engine crawling?
Every day we dump a lot of data into the www repository. Going back to our analogy, the librarian receives enormous amounts of books. To store the books into sections and in order of relevance, the librarian must get to know all the books. For the same reason, search engines have some robots/bots known as crawlers/spiders to get updated about the additions. These additions can be anything from a web page to an image. As we know, all the information on the internet is associated with a URL. These crawlers collect all the information and dump it in the database. Google’s database is called Caffeine.
If you have a website and it doesn’t show up in the SERPs, then there could be these possible issues for not crawling:
- If your website is brand new, wait for the crawlers to go through them. It usually may take up to 48 hours.
- Make it easy for crawlers to navigate. If your website has a lot of web pages, the crawlers might face difficulty in crawling through them. Therefore, you have to submit sitemaps to the bots to ease navigation.
- Google penalizes websites for using spammy techniques. So, be careful!!!!
- Your website might have code that is blocking the crawler.
Search Engines Consoles list all the issues with the website and provide suggestions to improve.
Robot.txt:
If you want a crawler to crawl your website in a particular way, you can give those instructions in a robot.txt file. Make sure to know the right way of using this file because if the crawlers don’t understand the file, they don’t crawl the whole web page. But when the instructions are clear, the crawler follows them.
Indexing: How do Search Engines store data?
What are XML sitemaps: how to create them?
NoIndex:
This is a method to secure your web pages that are not supposed to be indexed. You can hide the premium content pages and make them accessible to only logged-in users.
Ranking: what factors affect the ranking of a website?
To suggest the best book, the librarian shall consider relevance, reviews, number of readings etc. The librarian might have created a formula based on all these parameters to create a ranking order. Similarly, all search engines have created algorithms that have evolved to serve the user’s needs the best. The algorithms consider several factors like Technical SEO, On-page SEO and Off-page SEO. We will soon talk about all these topics in detail, but for now, let’s discuss a few basic metrics measured by search engines.
Relevance: Search engines always strive to match the results with the exact user query. If multiple websites or web pages match the search query, then it will consider other metrics.
Engagement: The engagement metrics include click-through rate (CTR), time spent on the website, Bounce rate: meaning visiting only 1 page and leaving, etc. Focus on good content and the users will love it!! As they always say, Content is King. Don’t fool your users and search engines. Both of them hate it!!!!!!
Link Juice: Link juice is the number of times a text points to a web page. You can link a text on a blog page to the home page on your website and these links are called internal links. There can also be some other websites which point to your website and these links are called backlinks.
Link Authority: You can get backlinks from multiple sources but are the sources genuine and good? Link authority is like the genuineness of a website and a website with backlinks from genuine websites has high link authority.

Here we are at the end! I hope you understood how the search engine works and also the various steps and factors related to it. In the coming blogs, we will talk more about SEO techniques and how to use them.
So, stay tuned!!!!